Python爬虫基础知识
网络爬虫是自动从互联网上提取信息的程序。使用Python编写爬虫已经成为一种流行的方法,因其简单易用且功能强大。了解基本概念和技术可以帮助开发者更有效地进行数据抓取。
环境准备与工具选择
要开始创建一个Python爬虫,需要安装一些必要的库,如Requests和BeautifulSoup。这两个库提供了发送HTTP请求及解析HTML文档的能力。此外,可以考虑使用Scrapy框架,它为大型项目提供了一整套完整解决方案,方便管理多个任务。
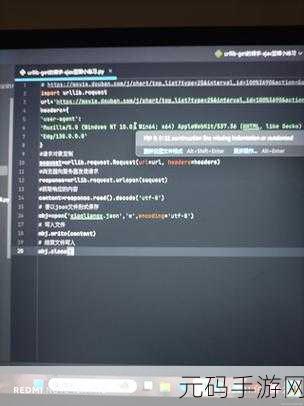
如何发起请求
Pythons Requests库能够轻松获取网页内容。通过发送GET或POST请求来访问目标网站,并获取返回的HTML代码。如果遇到需要处理Cookies、Headers或者代理的问题,Requests也能灵活应对。例如,通过设置User-Agent头部模拟浏览器行为,从而提高成功率并避免被封禁。
解析网页内容
拿到网页源码后,需要对其进行分析以提取所需的数据。这时就可以利用BeautifulSoup这个强大的解析器,通过查找标签、类名或属性等方式精准定位目标数据。在操作中,也可结合正则表达式进一步增强筛选效果,以适应复杂页面结构。
存储抓取的数据
Crawled data storage is crucial. A database如SQLite, MySQL 等,可用于高效存储和查询。同时,对于小型项目,将数据直接导出为CSV文件也是个不错选择。而对于实时性要求较高的信息,则可能考虑将结果推送到消息队列中,使得应用更加灵活与响应迅速。
Error Handling and Debugging Techniques
Pseudocode中的异常处理至关重要,因为在实际执行过程中难免会出现各种错误情况。当遭遇404(未找到)、403(禁止访问)等状态码时,应当妥善记录这些问题,同时实现重试机制,提高脚本稳定性。此外,调试过程尤为关键,可以借助日志模块输出不同阶段的信息,更加便于排错和优化性能。
User-Agent Spoofing Methods
User-Agent 是识别客户端软件类型的重要部分。一些网站根据 User-Agent 来决定是否允许某个用户继续访问,因此伪装成常见浏览器往往能够获得更多权限。有多种方法,比如随机切换 User-Agents 列表,这样更不容易触发反爬措施,同时保持良好的抓取效率以及速度体验。
Cautions Against Scraping Policies
Scrape a website without permission can lead to legal issues. Prior to crawling any site, always检查robots.txt文件,该文件指引哪些区域可供抓取,而哪些区域受限。同时尊重网站规定,不要过度频繁地向服务器发送请求,这不仅容易造成IP封锁,还可能影响其他用户正常访问信息。因此合理控制API调用频率显得十分重要.
- # 爬虫技术在自然语言处理中的应用
- # 如何防止机器人检测系统阻挡你的Crawler?
- # 数据隐私保护下的新一代Web scraping策略研究



